In Episode 83 of the now defunct Hashtagged Podcast, Jordan Powers interviews Tyson Wheat, who talked about the early days of Instagram. Back then (2011), he says, “You just needed 10 or so likes within 5 minutes to get onto the popular page.” Â When I heard this, I realized Instagram was gamed from the beginning. This isn’t saying that without enough hard work, luck and skill you couldn’t use Instagram in 2011 to launch a career. It’s just that already in 2011, you’re competing in the Tour de France with somebody that’s doping, or you’re in a sport where you’re competing with somebody on steroids. Instagram was never fair. The superb photos that ended up on the popular page back then sure had me fooled, though.

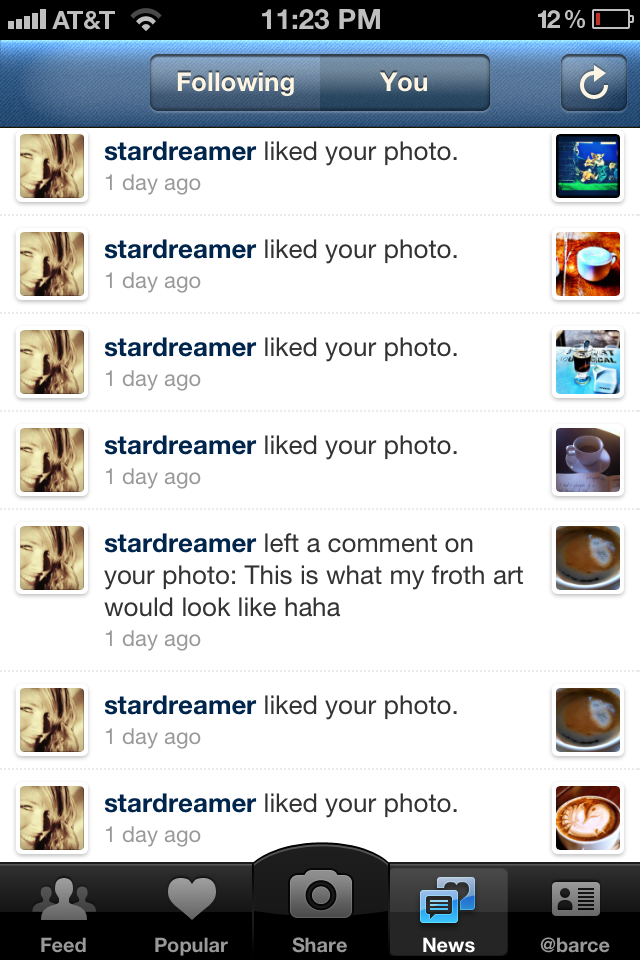
The first screenshot I have of Instagram from October of 2011
Hey, spamming likes to gain follows worked back then in 2011
By 2012, you could see that something was wrong in all social photo apps. People were gaming the system.
Hardwork and talent were still wonderfully rewarded on Insta back in 2011/2012.
In 2010, Sean Ellis coined the term growth hacking. Andrew Chen goes on at length in this classic article on what it means to be a growth hacker. For me though, growth hacking is finding flaws in the system and exploiting them in ways very similar to how the Russians tipped the 2016 election using hacking. So how did folks take advantage of the growth hacks on the popular page? In a similar way that diggs got monetized (Remember Digg?) the popular page on Instagram got monetized. According to Phil Gonzalez, a consortium of shady Turkish marketers would report a photo that naturally got to the popular page so it would get taken down, and then replace it with a post that got 100s of artificial likes from fake accounts within minutes.
But the popular page really didn’t help that much. I got on it once by posting around 8pm at my silent reading book club back in 2012. A few hundred likes and a score of follows rolled in finally pushing me above 100 followers. I had been stuck at below 100 for a year which is laughable now, but I’d have to say those first 100 followers were all awesome people and really great photographers. Eventually, Instagram would replace the popular page with the explore page, and basically had the algorithm dictate which photos got shown to whom on that page. But crappy photos selling the scam of the week (pills or bitcoin depending on the year) always seemed to find a way there every now and then.
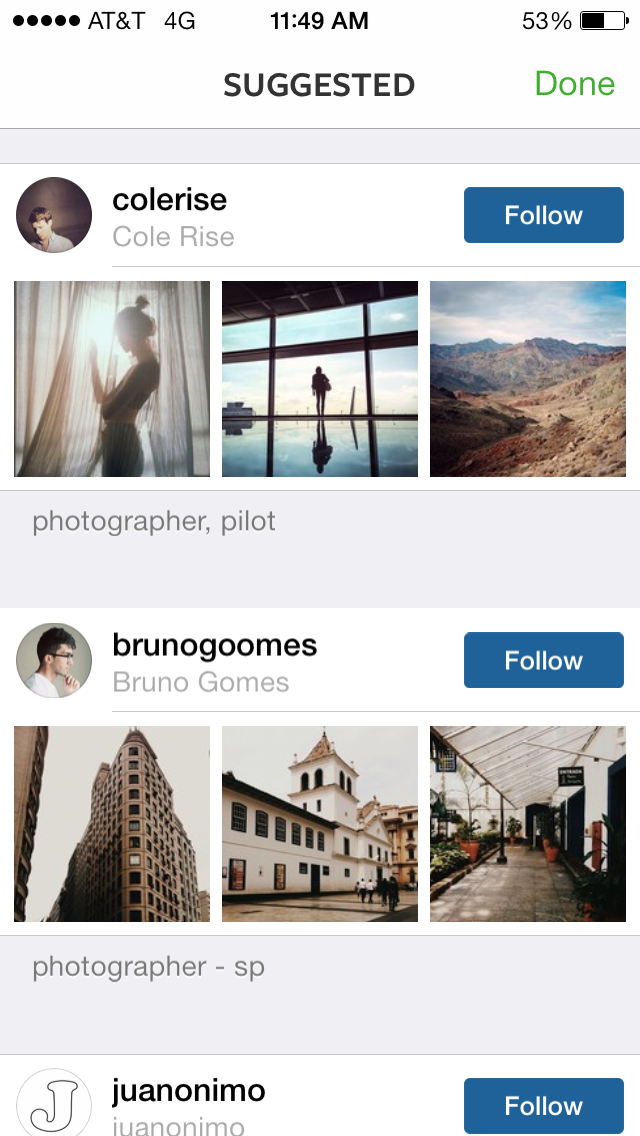
What really helped grow accounts was becoming a suggested user. Instagram could choose anyone and let them be suggested for at least two weeks to years. This meant that when people first signed up, the UI would strongly suggest that they follow the suggested user. You could grow at a rate of 10,000 followers a week as a suggested user.
How’d this dude get suggested on the bottom? His photos are so so.
The second way to grow would be to get a suggested user to follow you. This is where some shady paying for follows came in.
The 3rd way was doing a free for all where you gave photos to people, asked them to do their best edit, and you would choose photos to feature as long as they tagged you in the photo of yours that they posted.
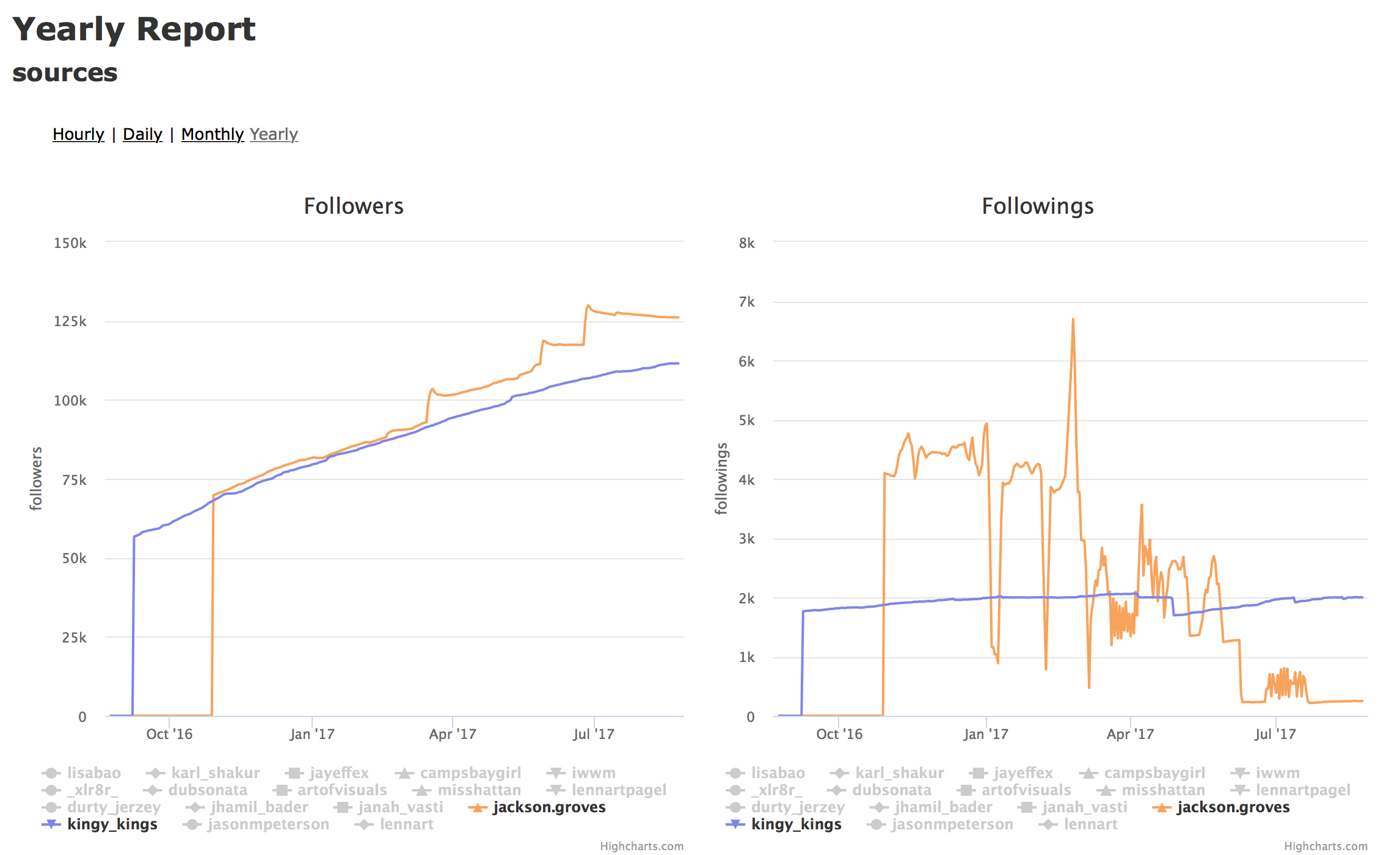
The 4th way, way back in 2012 was botting by using follow and unfollow. Companies like Massplanner which Instagram has now shutdown would sell these services for around 50 to 100 a month depending on how many followers you wanted. It’s not as shady as fake accounts since all you’re doing is suckering someone by following them, and then unfollowing them. Lots of folks have used this strategy from 2012 to 2016 to grow from 0 to 100,000 in a year. The downside is that your engagement is real low, and now that everybody is clued into it, your account just looks fake. The problem is folks who got suggested user back in the day, or coat-tailed off of them look just as fake. What’s even worse is that the algorithm for awhile gave the advantage to folks that botted. Here’s a chart showing that.
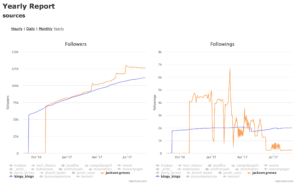
In blue @kingy_kings legit working hard to grow; in orange, @jackson.groves doing follow/unfollow by botting. The algorithm has them neck and neck, but then eventually the algorithm fails and rewards the cheater.
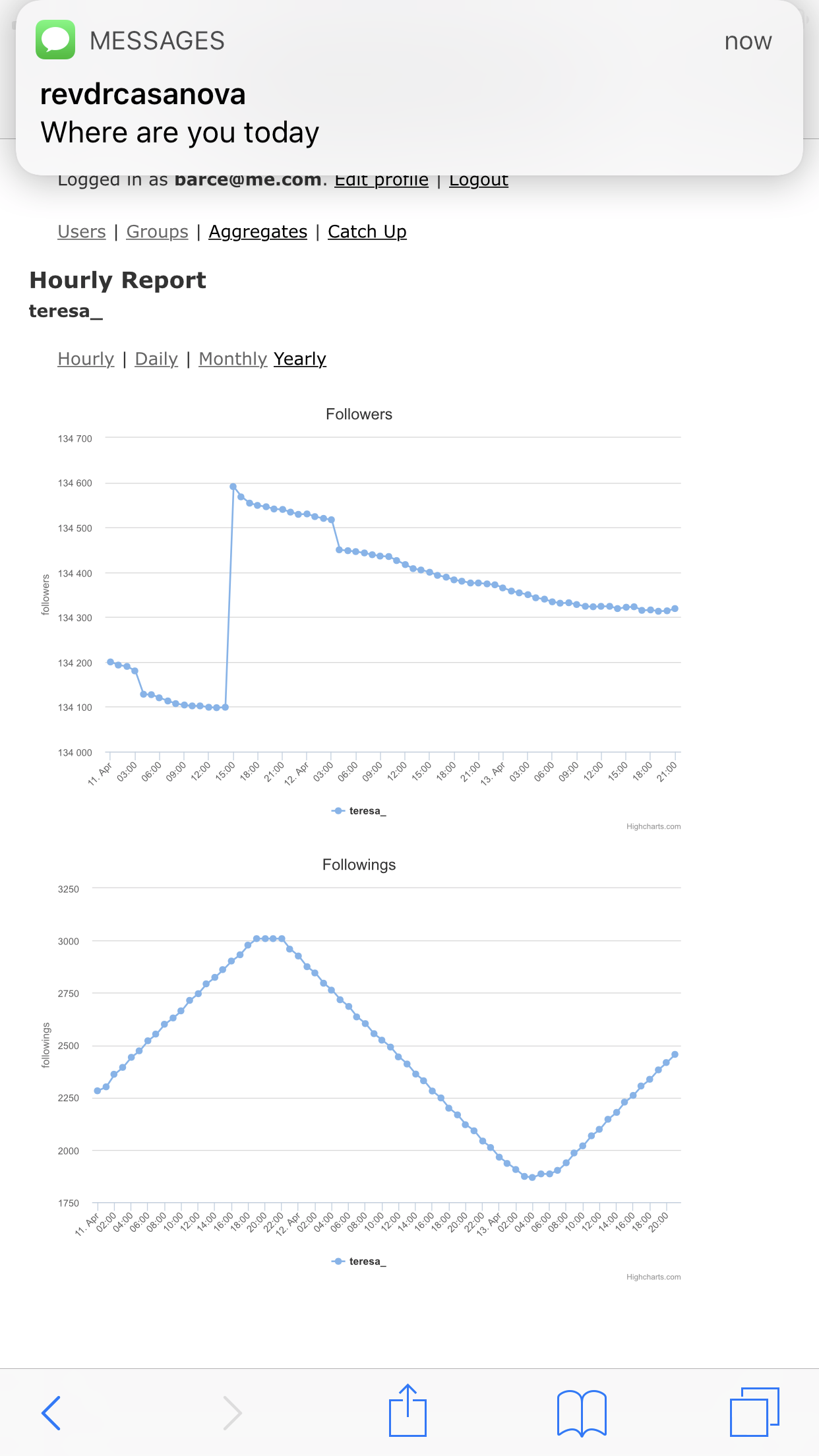
However by 2018, the algorithm would actually take away followers for botting, and it did this by feeding the botters to the botters as you can see in the chart below:
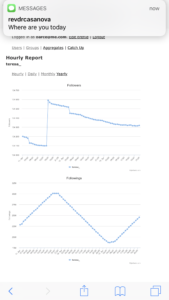
@teresa_ on Instagram is the worst. She’s botting and losing followers. lol
From 2016 to 2018 people would try the following to grow:
- power likes, getting a like from a large account
- paid features on huge accounts (1 million real followers or more)
- DM groups – these really help lots with engagement, but sentiment analysis can reveal who uses fake comments. This is true if you don’t shoot bangers. I’ve seen accounts with 1000s of cake photos, and each cake photo is the best cake photo that someone’s ever seen. The idea behind this is similar to the hack Tyson mentioned above. Get 5 or so comments in 15 minutes to get way more likes than if you didn’t get the comments.
- contests where you have to follow 20 to 40 people in order to enter
- contests that offered a free camera if you followed them
- follower networks where people grow multiple accounts to like and follow each other
- The Gary Vee 2 cent hack; this got killed when the algorithm detects this and just makes sure the Top Page you see is the same as the Recent Page
- getting a free feature from a large account
I’d say that the only strategy that works now is the last one which is just another way of saying “going viral.” Someone prove me wrong here, please.
The result of all this is that:
- people take the same photos as everyone else, i.e. InstaRepeat
- people take crappier photos than before
- people are taught by Instagram to game the system and society
This means Instagram is contributing to the downfall of society.
What should you do if you care about photography? Delete the app. Go back to making zines like I have. If you can’t bear to delete the app, just use it for the DMs.